What is String Tokenizer in Java?
The string tokenizer class allows an application to break a string into tokens. It is very easy to use.

old way:
New way:
It checks, if there are any more tokens available or not, if TRUE, prints the token, FALSE, terminates the loop.
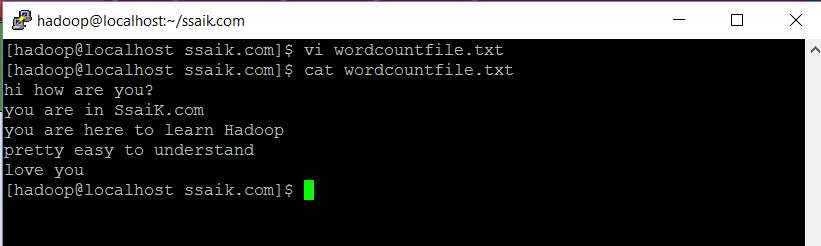
For example, if your file (test.txt) contain the content like
1| 3.29| mkyong
2| 4.345| eclipse
Output:
1| 3.29| mkyong
Id : 1
Price : 3.29
Username : mkyong
*******************
2| 4.345| eclipse
Id : 2
Price : 4.345
Username : eclipse
*******************

old way:
String[] result = "this is a test".split("\\s"); for (int x=0; x<result.length; x++) System.out.println(result[x]);
New way:
StringTokenizer st = new StringTokenizer("this is a test"); while (st.hasMoreTokens()) { System.out.println(st.nextToken()); }
It checks, if there are any more tokens available or not, if TRUE, prints the token, FALSE, terminates the loop.
System.out.println("---- Split by space ------"); while (st.hasMoreElements()) { System.out.println(st.nextElement()); System.out.println("---- Split by comma ',' ------"); StringTokenizer st2 = new StringTokenizer(str, ","); while (st2.hasMoreElements()) { System.out.println(st2.nextElement());
For example, if your file (test.txt) contain the content like
1| 3.29| mkyong
2| 4.345| eclipse
String line; br = new BufferedReader(new FileReader("c:/test.txt")); while ((line = br.readLine()) != null) { System.out.println(line); StringTokenizer stringTokenizer = new StringTokenizer(line, "|"); while (stringTokenizer.hasMoreElements()) { Integer id = Integer.parseInt(stringTokenizer.nextElement().toString()); Double price = Double.parseDouble(stringTokenizer.nextElement().toString()); String username = stringTokenizer.nextElement().toString(); StringBuilder sb = new StringBuilder(); sb.append("\nId : " + id); sb.append("\nPrice : " + price); sb.append("\nUsername : " + username); sb.append("\n*******************\n"); System.out.println(sb.toString()); } }
Output:
1| 3.29| mkyong
Id : 1
Price : 3.29
Username : mkyong
*******************
2| 4.345| eclipse
Id : 2
Price : 4.345
Username : eclipse
*******************